



General AI Assistant(GAIA): AI Agents Evaluation Benchmark.
Are reasoning and tools use abilities of AI Agents close enough to us?


We are way past traditional AI(predicting numbers and generating pixels). LLM can accurately predict the next word; thanks to transformer architecture and open-source contributions.
Predicting the next word is simply a combination of mathematical operations. How can we trust the response generated by LLM?
How can we measure whether the LLM is generating correct and reasonable responses?
Benchmarks….
Now What are benchmarks?
Think of them as evaluation or comparison metrics we use to assess the AI model’s performance by running standardized tests.
Many benchmarks have been developed recently with the AI boom to measure LLM responses.
New methodologies and techniques like supervised fine-tuning, reinforcement learning with human feedback, and more have emerged.
This emergence has led to the evolution of AI applications at an alarming pace, breaking all benchmarks.
Yeah, benchmarks are simple measures of how well a system or program is performing. What is so special about agentic benchmarks? Moreover, what is this GAIA now?
Unlike static AI models where input prompts generate responses. AI agents can plan, reason, and iteratively learn and execute multi-step tasks in real or simulated settings.
So, standard LLM benchmarks don’t cut it when evaluating AI agents. We need something robust and human-grade.
What is GAIA?
GAIA is a benchmark designed specifically for general AI assistants that evaluates the AI agent’s/LLM’s ability to handle real-world scenarios requiring multi-modality, reasoning, tools use, etc.
Why GAIA?
AI agents are getting better at simple tool use and multi-task reasoning abilities. Executing complex sequences of actions accurately with large combinatorial spaces is not possible yet.
We are getting there. So we need to turn up the heat a little and make this more challenging for AI. After all, it is AI for a reason and must exhibit exceptional capabilities for creative tasks that are time-consuming for humans.
How challenging is this new benchmark compared to existing ones like GLUE? This benchmark is slightly difficult for humans as it challenges LLMs with intricate assessments. It tests the LLM on many categories such as mathematical reasoning, common sense, tool usage, multi-modal tasks, and more.
The table below shows how good LLMs are at solving challenges in these categories compared to humans.
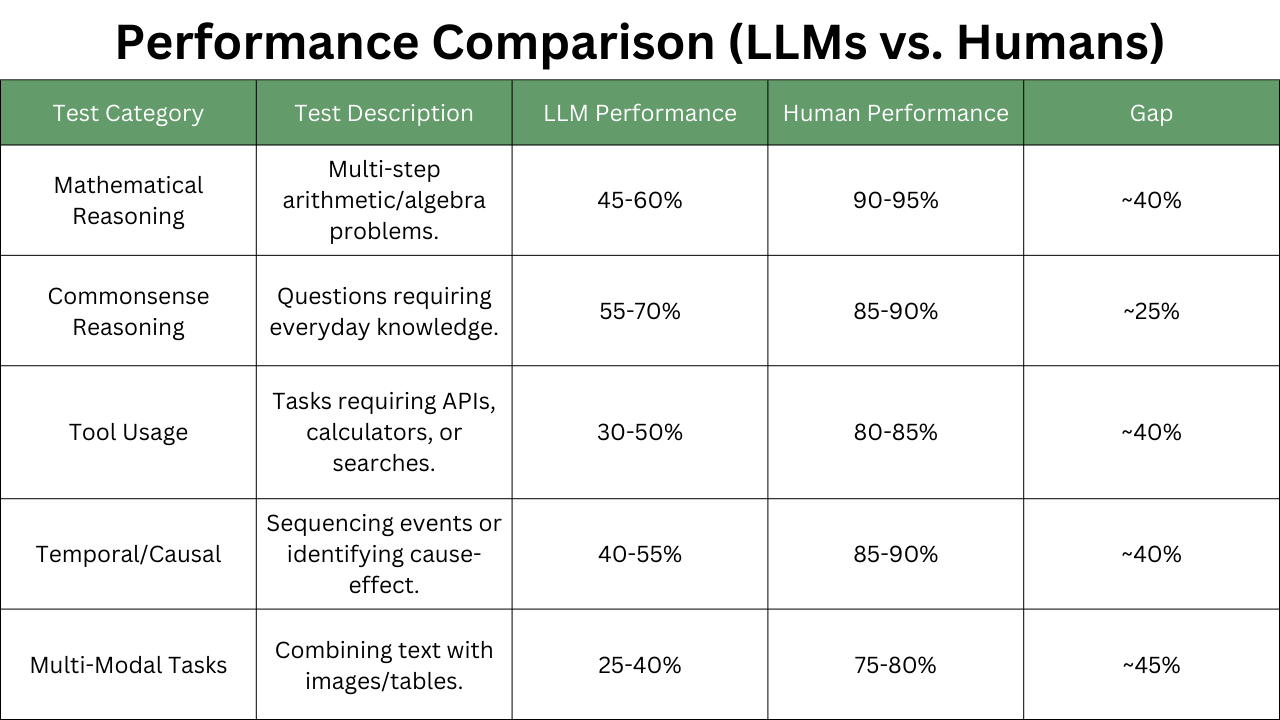
Some of the same questions probed to the AI agents are highlighted below. As we can notice answering these questions is not straightforward.
LLM needs to be better at completing tasks that require fundamental abilities.
The LLM reasoning capability, multimodality handling capability, and tool use proficiency must be off the charts to attain 100% accuracy.
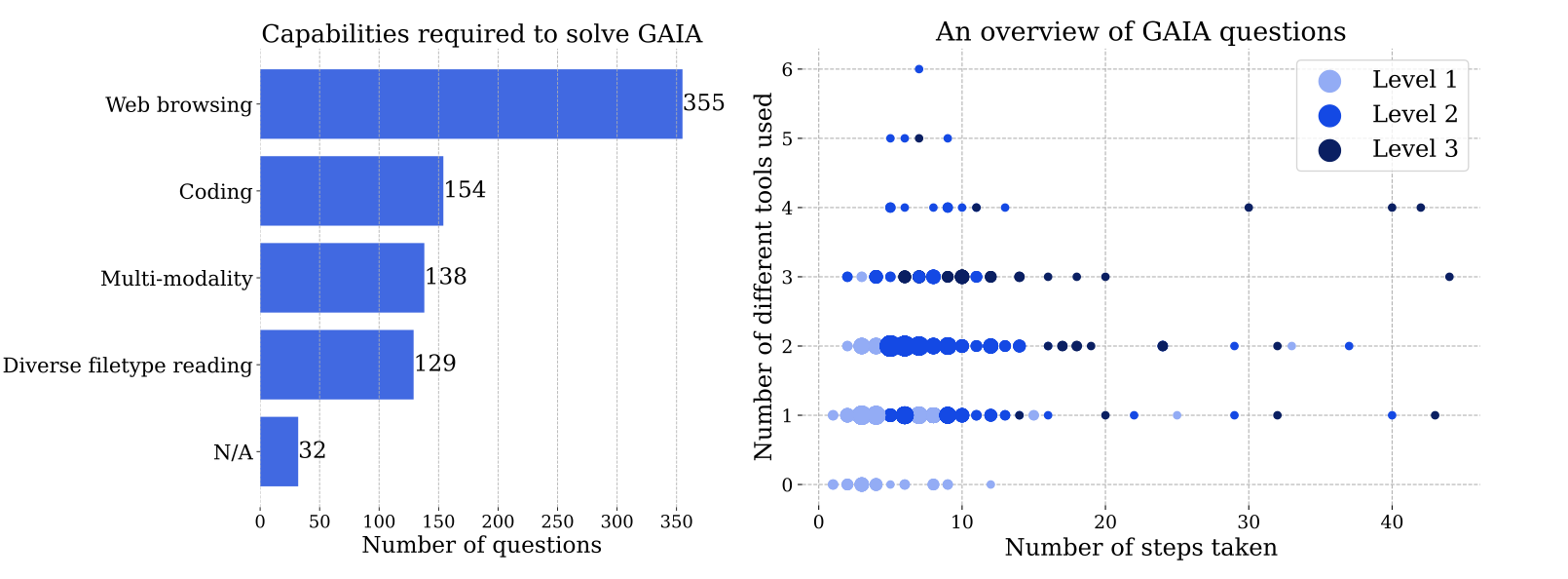
GAIA contains a total of 466 questions.
We need different levels of tooling and autonomy to solve these questions, so they are divided into three levels.

Have you heard about chatGPT’s Deep research?
The new tool introduced by chatGPT uses tools such as web search and applied reasoning to derive and deliver real-time information.
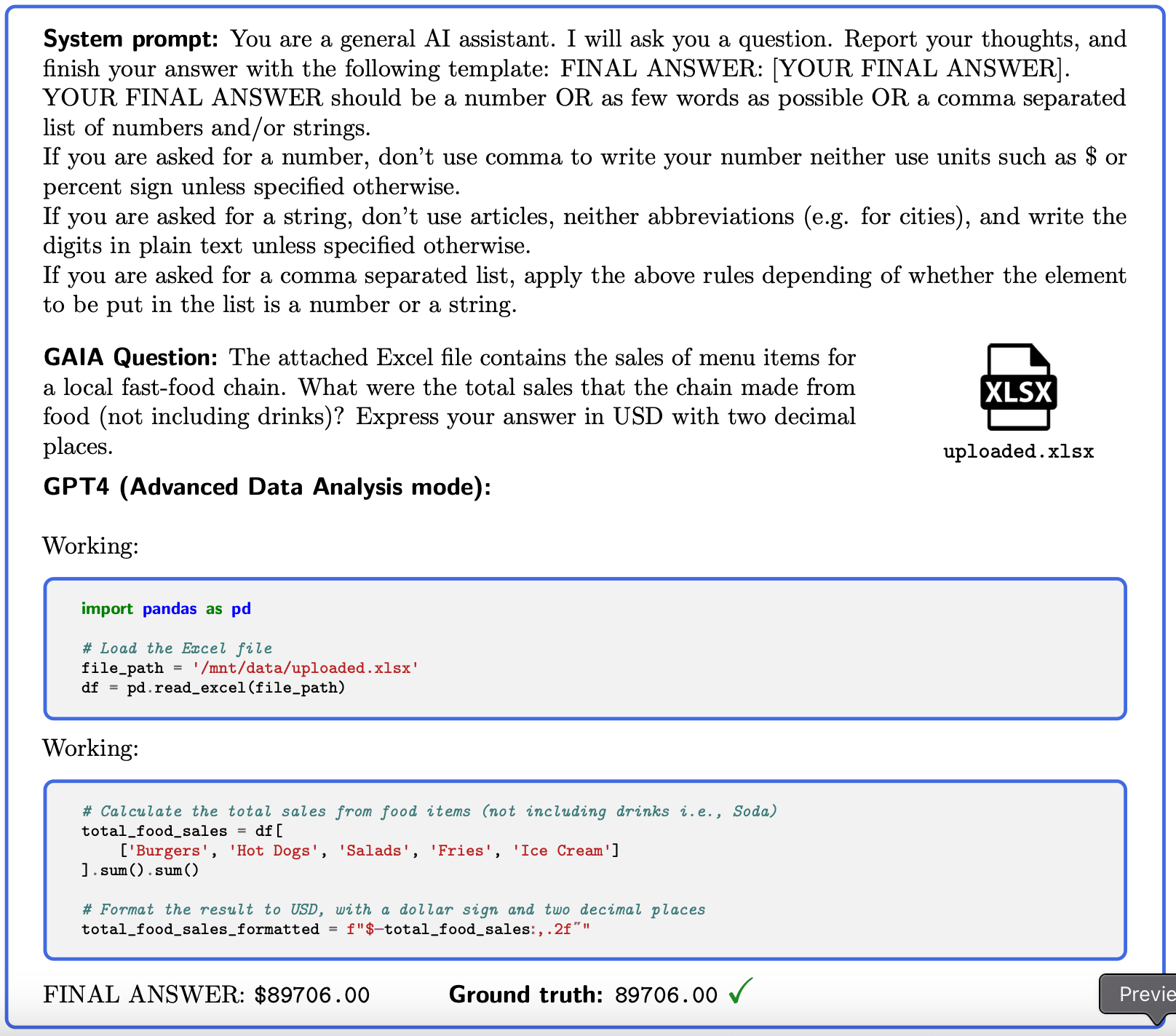
Here is a sample prompt and GAIA question asked to GPT4, notice the accuracy of the response.
How GAIA is Evaluated?
GAIA questions are simple yet efficient. They are designed so that LLM evaluation can be automated, factual, and fast.
Answers are expected to be a string, number, or comma-separated list of stings/floats/custom data types.
Every GAIA question has only one correct answer which is the ground truth. The Agent/LLM Model is probed to respond in the required format.
The response is evaluated against ground truth via a quasi-exact match
Are you building AI agents using open-source tools like crewAI or Agenta?
How good are your agents at multi-task reasoning and tools use?
Have you evaluated your LLMs and agents against GAIA benchmarks?
Try and let us know what you think about this new benchmark.
https://www.linkedin.com/company/nipunalabs/?viewAsMember=true
Thank you.