

Generate vector embedding from image text(optical characters)
Python Utilities to extract and load text from images into vector DB.


With exceptional possibilities and unparalleled functionalities, LLMs are taking the world by storm, thanks to vector databases and transformer architecture.
Data on the internet is getting scarce, organisations are focusing on generating LLM generated synthetic data to train their AI models.
Only time will tell how effective and useful these models are going to be.
Various data extraction methods have been emerged to address exploding data needs for Large language models training.
One of these extraction methods is to extract the text from the images. For example, understanding how much expenses were incurred by analysing the invoices, bills and snapshots.
Extracting the information is not enough, we need to chunk the data and generate embeddings for the generated chunks and upsert the embeddings into vector store.
Basic to most advanced libraries and tools exists to fulfil this requirement. But my focus here is to keep the process as simple as possible while leveraging efficient tech stack.
Pytesseract does the job for text extraction from the Images, Qdrant is promising and scalable enough to be used as a vector database and langchain has expanded exponentially with diverse functionalities to handle diverse use cases.
For step by step tutorial, please check out my video on Youtube.
We are going to understand the essence of the tool and walk through the reusable utility functions.
Pytesseract is inspired by google’s tesseract Optical character recognition (OCR) engine. With the OCR capabilities, the python library can easily read the text embedded in the images.
The library exposes various functionalities as shown below,
# Text from the image as String
pytesseract.image_to_string(Image.open('test.png'))
# French text image to String
pytesseract.image_to_string(Image.open('test-european.jpg'), lang='fra')
# Bounding box estimates
pytesseract.image_to_boxes(Image.open('test.png'))
# Verbose data including boxes, confidences, line and page numbers
pytesseract.image_to_data(Image.open('test.png'))
# Orientation and script detection Information
pytesseract.image_to_osd(Image.open('test.png'))We are interested in extracting text, but feel free to test other functions and get your hands dirty. For the utility, we will wrap the image_to_string call inside a function which accepts the image path and returns the text from the image.
import pytesseract
from PIL import Image
def extract_image_text(path: str):
text = pytesseract.image_to_string(Image.open(path))
return textLangchain, the viral python library that exploded in popularity with the rise of large language models (LLM) and generative AI (GenAI).
Langchain has many child libraries like langchain_community, langgraph, langchain_text_splitters and more. They package functionality for every use case into a python library and publish it.
We have following classes that offer unique functionalities to handle text data.
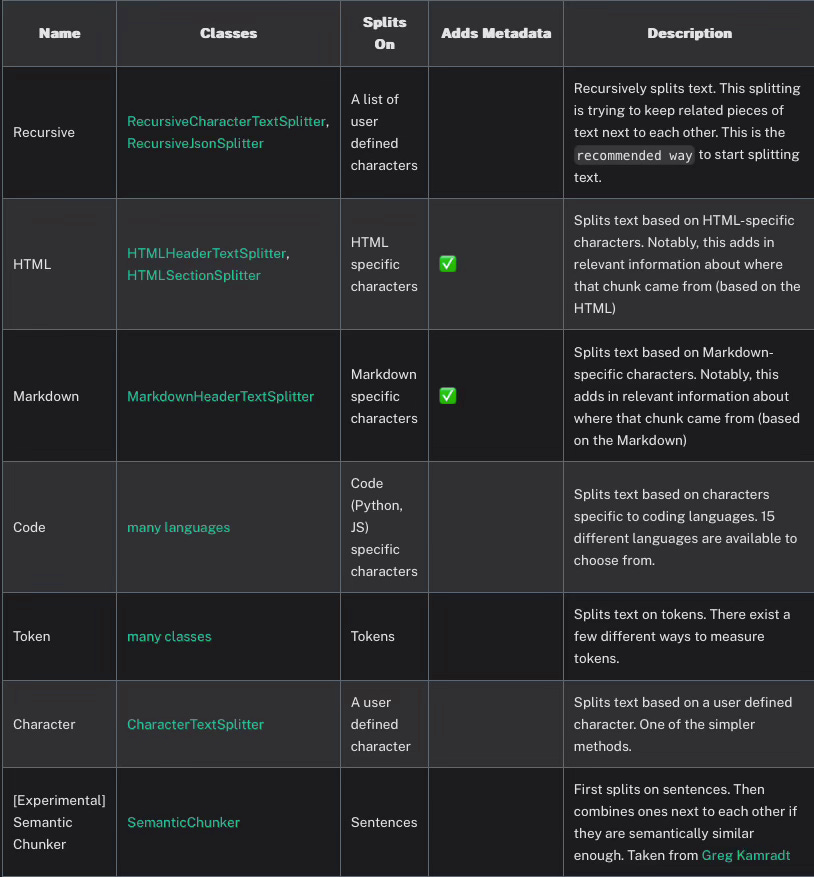
We will try langchain text splitter library to split our text as chunks.
import re
from langchain_text_splitters import CharacterTextSplitter
def generate_text_chunks(text: str):
text_splitter = CharacterTextSplitter(
separator="\n\n",
chunk_size=100,
chunk_overlap=20,
length_function=len,
is_separator_regex=False
)
text_chunks = [re.sub(r"[&\n]","" ,item) for item in text_splitter.split_text(img_content)]
return text_chunksQdrant, a vector database built with Rust is one of the popular open source vector database offerings out there. xAI used and forked the tool to handle their vector embeddings (not removed from their GitHub).
Although written in Rust, the tool has extensions in other languages and offers a docker image to provision and get started. With the below docker run command, we can start qdrant on post 6333.
docker run -p 6333:6333 -p 6334:6334 -v $(pwd)/qdrant_storage:/qdrant/storage:z qdrant/qdrantIn addition to awesome vector database, qdrant also offers embedding library fastembed. This library converts text chunks into embedding that can be upserted into the database for arithmetic use cases.
Mathematical operations like DOT, EUCLID, MANHATTAN and COSINE can be applied on the embeddings to perform similarity search and other arithmetic operations.
The class definition below is structured in a way that it can connect to qdrant client, generate embeddings and upsert them with a single function call.
from fastembed import TextEmbedding
from qdrant_client.models import PointStruct
from typing import List
from qdrant_client import QdrantClient
from qdrant_client.models import Distance, VectorParams
from tika import parser
class QdrantUtils(object):
def __init__(self):
pass
def client_setup(self, collection_name: str, distanceFunction: str):
distance_functions = {
"dot": Distance.DOT,
"cosine": Distance.COSINE,
"euclid": Distance.EUCLID,
"manhattan": Distance.MANHATTAN
}
client = QdrantClient(url="http://localhost:6333")
if not client.collection_exists(collection_name=collection_name):
vectors_config = VectorParams(size=384, distance=distance_functions[distanceFunction])
client.create_collection(
collection_name=collection_name,
vectors_config=vectors_config
)
return client
def parse_pdf(self, file_path: str):
parsed_content = parser.from_file(filename=file_path)
stripped_content = [item for item in parsed_content["content"].splitlines() if item != '']
return stripped_content
def generate_embeddings(self, embeddings_lst: List[str]):
embedding_model = TextEmbedding()
embeddings = list(embedding_model.embed(embeddings_lst))
return embeddings
def upsert_embeddings(self, collection_name: str, embeddings_lst: List[str]=None, distanceFunction: str = "dot",from_pdf: str = None):
client = self.client_setup(collection_name=collection_name, distanceFunction=distanceFunction)
if embeddings_lst is not None:
embeddings = self.generate_embeddings(embeddings_lst)
else:
embeddings = self.generate_embeddings(self.parse_pdf(from_pdf))
embeddings_lst = self.parse_pdf(from_pdf)
point_items = []
for i, (e, p) in enumerate(zip(embeddings, embeddings_lst)):
e = e.tolist()
items = PointStruct(id=i+1, vector=e, payload={f"text_{i}": p})
point_items.append(items)
upsert_action = client.upsert(
collection_name=collection_name,
wait=True,
points=point_items
)
return upsert_actionAdditionally, we can read and parse PDF files and generate embeddings for the text from parsed PDF files. To leverage the PDF parsing capabilities, make sure to spin up TIKA client with docker locally.
docker run -d -p 9998:9998 apache/tikaIf you liked the post, please support by subscribing to the page and share it with those who you believe can benefit from this post.
Thank you and Stay in touch..
https://www.linkedin.com/in/jayachandra-sekhar-reddy/
https://x.com/ReddyJaySekhar